Startup Portfolio
Chalk AI 機械学習でデータインフラをシームレスに処理し、クラス最高の開発者体験を提供
Chalkは、革新的な機械学習チームが、ビジネスを際立たせるユニークな製品やモデルの構築に集中できるようにします。その裏では、Chalkがデータインフラをシームレスに処理し、クラス最高の開発者体験を提供します。その仕組みは次のとおりです。
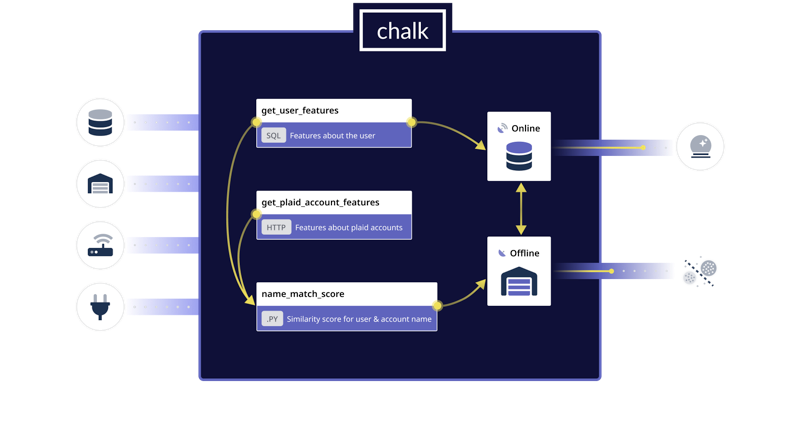
Chalkは、機械学習のためのフィーチャーパイプラインを簡単に開発することができます。特殊なDSLではなく、使い慣れたライブラリやツールを使ってPython関数を定義します。そして、Chalkは、関数をRustベースのエンジンで並列実行するパイプラインに編成し、特徴量を計算するために必要なインフラを調整します。
まずはPydanticにインスパイアされたPythonクラスで機能を定義しましょう。スキーマを定義し、関係を指定し、メタデータを追加することで、チームで仕事を共有し再利用するのに役立ちます。
次に、Chalkに特徴量を計算する方法を指示します。Chalkは既存のデータストアからデータを取り込み、Pythonを使って特徴量解決器を用いて特徴量を計算することができます。特徴解決器は@onlineと@offlineというデコレーターで宣言され、他の特徴解決器の出力に依存することができます。リゾルバは、様々なデータソースを迅速に統合し、それらを結合し、モデルで使用することを容易にします。
特徴量とリゾルバを定義すると、Chalkはそれらを柔軟なパイプラインに編成し、モデルのトレーニングや実行を容易にします。
Chalkはフィーチャーエンジニアリングのワークフローをビルトインでサポートしています。Airflowを管理したり、複雑なストリーミングフローをオーケストレーションしたりする必要はありません。また、リゾルバパイプラインを宣言型キャッシュで実行したり、バッチデータをスケジュール通りに取り込んだり、低レイテンシで提供するために遅いソースをオンラインで簡単に利用できるようにしたりすることができます。
多くのデータソース(ベンダーのAPIなど)は、オンラインのユースケースには遅すぎるか、1回あたりの通話料が高い。Chalkは、システム全体にうまく統合された宣言型のキャッシュポリシーを定義することで、レイテンシーとコストを最適化できます。Redis、Memcached、DynamoDBなどのデータソースを管理したり、キャッシュウォーミングパイプラインのチューニングに時間をかけたりする必要はもうありません。
Chalkは、お客様のデータソースと統合し、フィーチャーパイプラインでデータを変換し、このデータをオンラインとオフラインのストレージに保存し、フィーチャー計算と分布に関するモニタリングを提供します。
デフォルトでは、ChalkはSaaSサービスとして動作し、Chalkはパイプラインを実行し、データをクラウド基盤上に保存します。しかし、Chalkはそのソフトウェアをお客様のAWSやGCPプロジェクトにデプロイすることも可能です。このモデルでは、環境はTerraformを介してプロビジョニングされ、Chalkのチームによって管理されます。
関連ニュース






Chalk AI に興味がありますか?
最新ニュース
AIエージェント時代向けのデザインプラットフォームを開発する"Paper"がSeries Aで$34Mを調達
2026/07/27
スウェーデン発でインテリジェントなメール受信トレイを開発する"Scape"がSeedで$3.2Mを調達
2026/07/27
AIエージェントを活用してスピアフィッシングと呼ばれる脅威を排除するメールセキュリティの"AegisAI"がSeries Aで$36Mを調達
2026/07/24
産業企業がミッションクリティカルな業務へAIエージェントを導入することを支援する"Arrakis"がSeries Aで$30Mを調達
2026/07/24

スイス発で血圧モニタリングプラットフォーム開発する"Hilo"がSeries Bで$19Mを追加し累計で$119M超を調達
2026/07/24